

INTRODUCTION
A novel coronavirus was first documented on December 30, 2019, through the Program for Monitoring Emerging Diseases (ProMED-mail). The report stated that the Medical Administration of the Wuhan Municipal Health Committee had issued “an urgent notice on the treatment of pneumonia of unknown cause in Wuhan, China” (1, 2). On January 8, 2020, the pathogen was identified as a novel coronavirus, later named severe acute respiratory syndrome coronavirus 2 (SARS- CoV-2) (3). The virus spread rapidly worldwide, posing significant threats to public health.
According to Google Trends, “coronavirus” dominated global search activity in 2020, with peak interest observed in Italy between March 15 and 21. The pandemic heightened public awareness of the need for prompt preventive measures. Researchers from multiple disciplines conducted extensive studies on coronavirus disease 2019 (COVID-19) (4, 5), resulting in over 1,000,000 publications. Indeed, COVID-19 accounted for the majority of scientific papers published in 2020 (6).
Predictive modeling is one of the most widely studied applications of data science in infectious disease research. Previous studies explored forecasting outbreaks in specific regions—for example, predicting dengue fever incidence across 20 cities in China using long short-term memory (LSTM) neural networks (7), or anticipating COVID-19 cases in ten Brazilian states with machine learning techniques (8). Other researchers incorporated non-pharmaceutical interventions and cultural metrics (9), or social media data such as tweets (10). As artificial intelligence (AI) continues to expand its scope (11), it is facilitating faster responses across many fields, including infectious disease research. However, the effectiveness of AI fundamentally depends on data acquisition. Prior researches have confirmed that the volume and quality of data critically influence the performance of machine learning-based prediction models (12, 13, 14), particularly in time-series forecasting, where training on the most up-to-date data is essential (15, 16, 17, 18).
However, collecting up-to-date structured datasets remains challenging, especially in the early stages of outbreaks, due to time-intensive preprocessing. By contrast, unstructured textual data, such as news articles and press releases, are often available immediately. As noted earlier, ProMED-mail initially reported COVID-19 as “undiagnosed pneumonia” (2), and web-based monitoring systems such as MedISys and the World Health Organization (WHO) issue early alerts about emerging disease X (19). Communicable disease reports are also published regularly by WHO, the European Centre for Disease Prevention and Control (ECDC), the Pan American Health Organization (PAHO), and national health departments.
Several studies have explored using these media sources as datasets for epidemic analysis and forecasting (20, 21, 22). Thus, monitoring both structured and unstructured textual data from diverse sources is essential. However, manually inspecting and collecting such data at scale is impractical. To address this, we investigated the use of named entity recognition (NER) techniques to automatically extract key information from unstructured text.
Among natural language processing (NLP) tasks, NER extracts information from text by identifying entities and classifying them into predefined categories such as person, location, and date (23, 24). Traditional NER methods include deep neural networks such as convolutional neural networks (25), LSTM networks (26), and embeddings from language models such as ELMo (27). More recently, transformer-based language models have become dominant in NER research (28, 29), including bidirectional encoder representations from transformers (BERT) (30) and the generative pre-trained transformer (GPT) (31). With advances in computing power and language models, the application domains of NER have broadened diversely (32, 33).
Biomedical NER has been extensively studied in the context of biomedical literature, including entities such as drugs (34), proteins (35), and genes (36). In recent years, many researchers have adopted BERT-based approaches for biomedical NER tasks (37, 38). One study also developed an NLP pipeline to identify COVID-19 outbreaks from public health interview forms (39), demonstrating the superior performance of the BERT model.
Despite these advances, benchmark NER datasets for infectious disease surveillance remain scarce, even though NLP research in this field is urgently needed (40). For instance, one study created a Spanish event-based surveillance system using recurrent neural networks (41), while another introduced the Global Infectious Diseases Epidemic Information Monitoring System using epidemic websites (42).
To address this gap and enhance applicability in public health contexts, we propose Survice-BERT, a BERT model for biomedical NER in infectious disease surveillance reports. The model leverages a pre-trained BERT architecture and a novel dataset constructed by extracting key information from global surveillance reports in PDF format. Survice-BERT is designed to identify, extract, and classify critical outbreak-related information from unstructured text. To the best of our knowledge, this is among the first attempts at fine-tuning a pre-trained BERT model on datasets derived from infectious disease surveillance reports annotated with NER tags such as disease names, case counts, death counts, and outbreak dates. Moreover, we anticipate that the presented model has the potential to serve as a useful paradigm for surveillance data collection systems.
METHODS
This section describes the architecture, dataset construction, and training pipeline of Survice-BERT, a biomedical domain- specific BERT model fine-tuned for NER on infectious disease surveillance reports.
Model Architecture
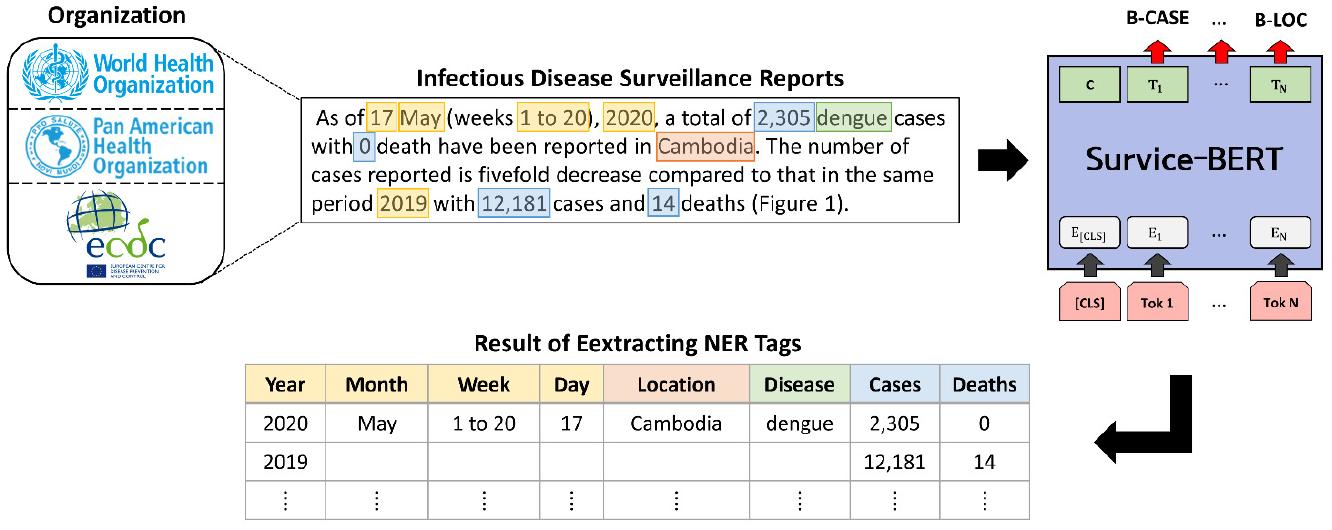
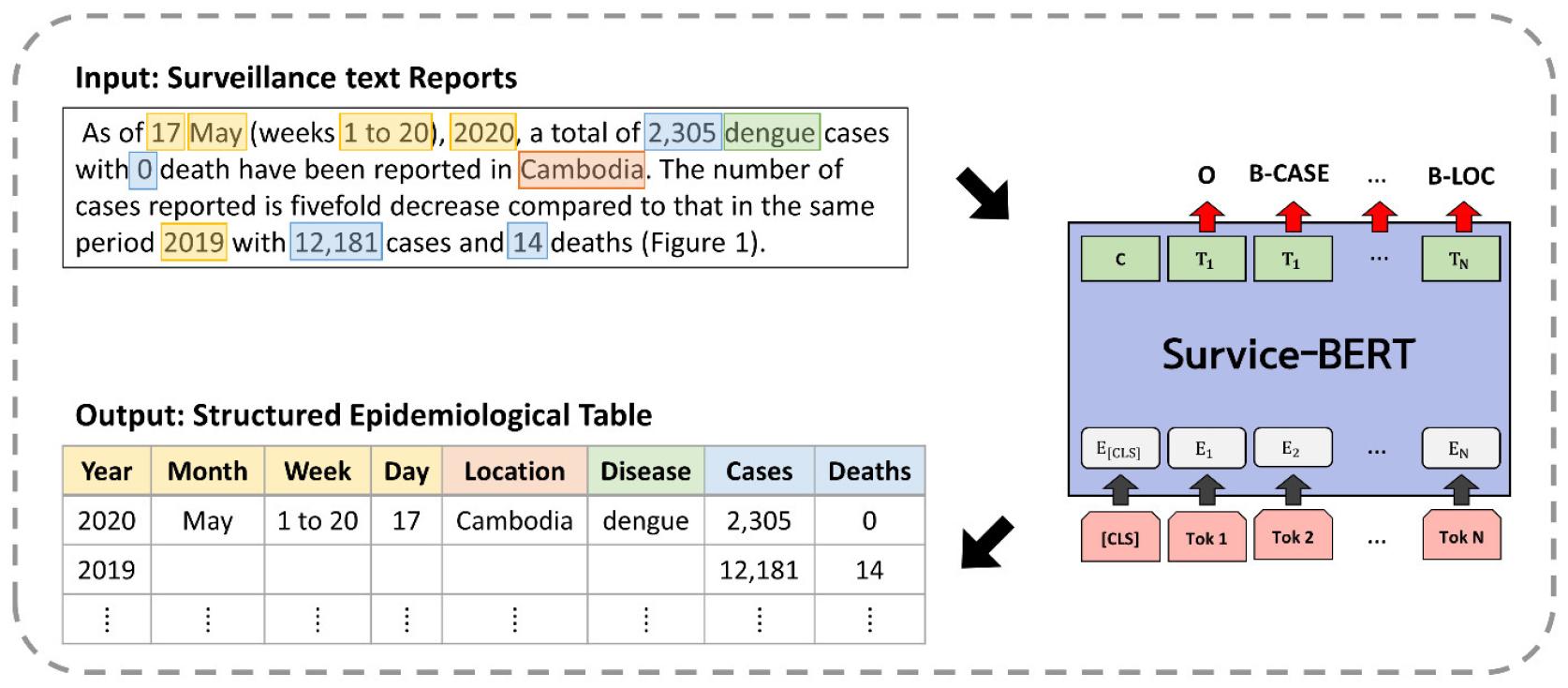
Fig. 1 presents the workflow of Survice-BERT. The model receives unstructured surveillance reports as input and first splits the text into sentences based on punctuation. It then tokenizes each sentence, identifies tokens corresponding to predefined named entities, and categorizes the outputs into structured tables. These tables can subsequently be applied in downstream tasks such as epidemic monitoring and prediction.
Pre-trained Language Model: BERT
In 2019, Google introduced BERT, a pre-trained language model (PLM) trained on large general corpora, including BookCorpus and English Wikipedia (30). Unlike GPT (31), which is trained unidirectionally, BERT employs bidirectional self-attention. Its adaptability has made it widely used across domains, leading to the development of domain-specific BERT models, including:
•BioBERT: Pre-trained on biomedical literature such as PubMed abstracts and PubMed Central full-text articles (43). It has achieved state-of-the-art performance in biomedical relation extraction, question answering, and NER using datasets such as NCBI Disease (44), BC5CDR (drug and chemical entities) (45), JNLPBA (genes and protein entities) (46), and LINNAEUS (species name recognition) (47).
•SciBERT: Pre-trained on a large corpus of scientific publications from Semantic Scholar (48). Designed to address the scarcity of high-quality labeled scientific data, SciBERT enhances performance on scientific and biomedical NLP tasks (49) using datasets such as BC5CDR (45), ChemProt (50), and EBM-NLP (51).
•Other models: DNABERT (52), ClinicalBERT (53), MT-Clinical BERT (54), and PubMedBERT (55).
In this study, we fine-tuned BioBERT and SciBERT, two widely used domain-specific BERT models for biomedical NERusing our custom datasets derived from communicable disease reports.
Fine-tuning Framework: NERDA
We used NERDA, a Python-based framework built on PyTorch and Hugging Face Transformers, to fine-tune the models for NER (56). NERDA provides an intuitive interface for fine-tuning transformer models on user-defined datasets with configurable hyperparameter settings.
Dataset Construction
A new NER dataset was developed due to the lack of publicly available resources containing the specific target entities required for modeling. The dataset follows the CoNLL-2003 benchmark format (57), consisting of sentence–tag pairs annotated using the BIO tagging scheme.
A Python-based crawler and parser were implemented to automatically download infectious disease surveillance reports in PDF format from three major organizations and convert them into plain text. Examples of extracted sentences include:
•ECDC: Communicable Disease Threats Report (e.g., “On 17 March 2023, the Ministry of Health of Tanzania reported seven people affected by an undiagnosed disease in Kagera, northern Tanzania, including five deaths and two people treated at hospitals”) (58, 59).
•PAHO: COVID-19 Daily Update Report (e.g., “According to the latest Uruguay Ministry of Public Health report, the total notes 10 positive cases reported in the last 24 hours were excluded from the total”) (60, 61).
•WHO: Dengue Situation Report (e.g., “As of epidemiological week 17 of 2023, 129 dengue cases were reported in Singapore, leading to a total of 2,857 cases”) (62, 63).
Tokenization was performed using spaces and punctuation, except for commas in numeric values representing case and death counts. We defined eight NER tags relevant to disease outbreak monitoring: DATE (including YEAR, MONTH, WEEK, and DAY), LOCATION, DISEASE_NAME, CASE, and DEATH. Each sentence was manually annotated with these tags. For indirect expressions such as “this year,” the token “this” was annotated as a DATE entity. Since the annotations were conducted by a single researcher, no inter-annotator agreement score was calculated. Fig. 2 shows the structure and example annotation of the datasets.
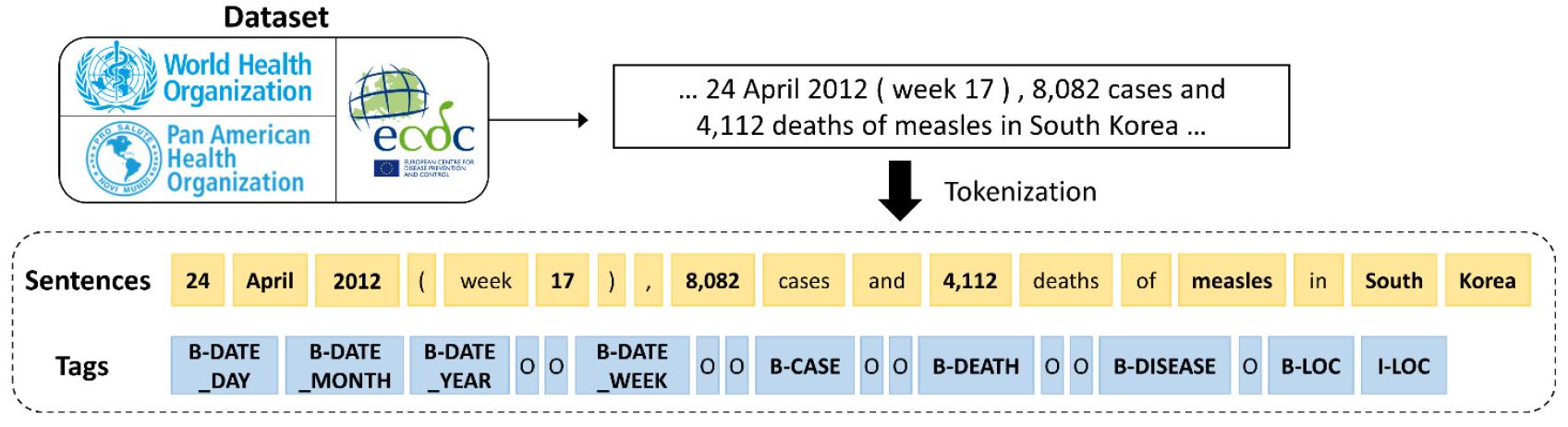
Fig. 2
Structure and annotation example of the proposed datasets. Sentences were derived from three types of reports, and eight named entities were annotated using BIO tagging with B (beginning), I (inside), and O (outside), depending on position.
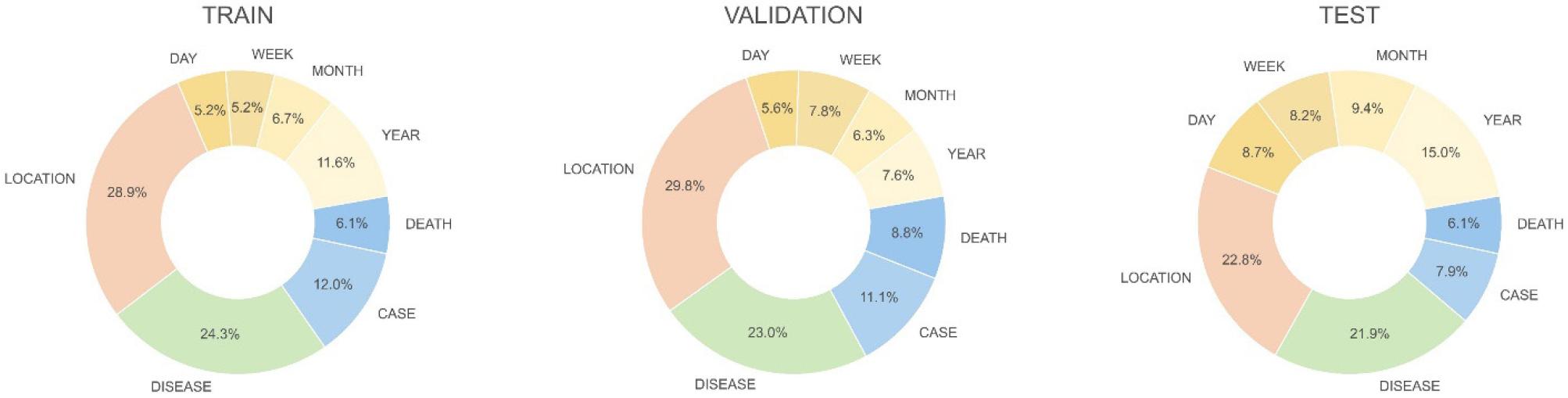
To mitigate overfitting and enhance generalizability, the training, validation, and test sets were constructed from different report sources, following approaches reported in prior studies (64). To further diversify the data, augmented sentences were generated by modifying country and disease names. There were no duplicate sentences across the datasets. The final dataset comprised 4,200, 1,400, and 1,400 sentences for training, validation, and testing, respectively (Table 1). Two versions of the dataset were also created to assess the effect of comma usage in numeric values for cases and deaths counts: one with commas and one without. Table 2 summarizes the counts of NER tags in each dataset, and Fig. 3 presents their distribution across the datasets.
Table 1.
Description of our datasets
| Dataset | Name of Report | No. of Sentencesa | Ratio | Ref | Date of Use |
|---|---|---|---|---|---|
| Train | Communicable Disease Threats Report | 4,200 | 60 | ECDC | Week 6 2012–Week 21 2012 |
| Validation | COVID-19 Daily Update Report | 1,400 | 20 | PAHO | 26 Jan 2020–2 Mar 2020 |
| Test | Dengue Situation Report | 1,400 | 20 | WHO | Report No. 458–462 |
a: Sentences are the constituent elements of the datasets shown in Fig. 2.
Model Training
We fine-tuned two biomedical domain-specific pre-trained BERT models, BioBERT and SciBERT, on our custom infectious disease NER dataset. To evaluate format robustness, each model was trained on two dataset versions—one with commas in numeric values and one without—resulting in four model variants (Table 3).
Table 3.
Four model variants used in this study
| V1 | V2 | V3 | V4 |
|---|---|---|---|
| BioBERT | BioBERT | SciBERT | SciBERT |
| Without commas | With commas | Without commas | With commas |
The models were fine-tuned using the NERDA framework. A total of 40 experiments were conducted by varying batch sizes and learning rates as shown in Table 4, following configurations recommended in earlier BERT studies (30, 43, 44). Model training was performed for 10 epochs on the Neuron supercomputing system at the Korea Institute of Science and Technology Information. The experimental settings are listed in Table 5.
RESULTS
We fine-tuned four model variants, combining two pre-trained BERT models with two dataset formats. Each model was trained for 10 epochs with varying batch sizes and learning rates on the Neuron supercomputer. In addition, we constructed new datasets for detecting outbreak-related entities, including LOCATION, NAME, CASE, DEATH, and DATE.
To evaluate model performance, we used the F1-score, the standard metric for NER. Table 6 presents the micro-averaged F1-scores of the models across datasets. Performance was highest on the training data derived from ECDC reports, followed by the data of test (WHO) and validation (PAHO). The F1-scores for the training set were all 1.00. Test scores were consistently above 0.90, while validation scores were comparatively lower. Supplementary experiments confirmed that fine-tuning on separate training, validation, and test datasets yielded higher F1-scores than training on an integrated dataset.
Table 6.
F1-scores of the best models by dataset (V1: BioBERT w/o commas, V2: BioBERT w/ commas, V3: SciBERT w/o commas, V4: SciBERT w/ commas)
| Model | V1 | V2 | V3 | V4 |
|---|---|---|---|---|
| Dataset | ||||
| ECDC (training) | 1.000 | 1.000 | 1.000 | 1.000 |
| PAHO (validation) | 0.967 | 0.956 | 0.941 | 0.963 |
| WHO (test) | 0.991 | 0.992 | 0.990 | 0.993 |
The best configuration for each model was further evaluated on the WHO test dataset, using a learning rate of 3e−5 and a batch size of eight. Table 7 summarizes the F1-scores per NER tag across model variants. The V4 model (SciBERT with commas) achieved the highest overall F1-score (0.993). Although V4 outperformed the other models overall, BioBERT achieved higher scores on certain tags, such as CASE, DEATH, and DATE_WEEK. Conversely, SciBERT performed better on tags such as DATE_MONTH and DATE_DAY.
Table 7.
F1-scores of model variants on WHO reports by entity tag
We also compared results across dataset versions with and without commas in numeric values of cases and deaths. For the DEATH tag, models trained without commas (V1 and V3) achieved higher F1-scores, whereas for the CASE tag, models trained with commas (V2 and V4) performed better.
To validate practical applicability, we tested V2 and V4 on sentences not used during training, sourced from ProMED-mail and WHO Outbreak News (65, 66). Example inputs include:
•A total of 3 cases of MVE virus infection and 2 deaths have been reported in Victoria this mosquito season.
•From 1 November 2022 to 27 January 2023, a total of 559 cases of meningitis (of which 111 are laboratory confirmed), including 18 deaths (overall CFR 3.2%), have been reported from Zinder Region, southeast of Niger, compared to the 231 cases reported during 1 November 2021 to 31 January 2022.
The results matched the actual values without an O tag, as shown in Table 8. The V4 model correctly extracted all entity tags, whereas V2 misclassified this and mosquito in the first sentence. The error associated with this may result from annotation patterns during training, since phrases like this year were consistently labeled as a DATE entity, potentially causing contextual confusion in similar cases. The error with mosquito is likely due to annotation patterns involving relatively long I-LOC sequences in the dataset, which reduced sequence-level precision in NER tasks.
Table 8.
Results of extracting infectious disease outbreak information from ProMED-mail and WHO Outbreak News
DISCUSSION
In this study, we presented Survice-BERT, a BERT-based model fine-tuned for biomedical NER in infectious disease surveillance reports. We also constructed a novel benchmark dataset from global public health reports, annotated with eight predefined NER tags. Experimental results demonstrated robust performance, with the V4 model (SciBERT with commas) achieving an average F1-score of 0.993, surpassing previous studies (41). Survice-BERT effectively extracts critical details such as time, location, and disease name from outbreak reports, providing structured outputs that support sustainable monitoring, analysis, and forecasting in epidemic research.
The COVID-19 pandemic underscored the critical importance of early detection of emerging infectious diseases. However, most countries remain insufficiently prepared, particularly for unfamiliar pathogens (67). In this context, imminent contagion in public health demands rapid and intelligent responses. For example, since May 2022, monkeypox outbreaks have emerged worldwide, including in non-endemic countries (68). Such concurrent outbreaks highlight the need for preemptive surveillance strategies (69). Recently, the rapid advancement of AI technologies has facilitated their integration into policy-making processes to strengthen continuous monitoring and early detection (70).
From a methodological perspective, this study shows that fine-tuning a domain-specific PLM can achieve high performance on a relatively small dataset within a short training time, effectively reducing the burden of manual surveillance. It also demonstrates the advantages of source-specific dataset separation and highlights the utility of our dataset as a benchmark resource. Furthermore, the findings emphasize the potential of adapting BERT-based models to broader biomedical NER tasks.
Nevertheless, several limitations remain. Due to the structured orthography of the dataset, preprocessing of input sentences is necessary to ensure compatibility. Currently, Survice-BERT can extract information only from English texts; extending it to multilingual datasets or incorporating translation functions during preprocessing will enhance its applicability. In addition, due to the nature of the report, indirect expressions, such as last month and this week, exist. Therefore, these should be normalized by introducing a post-processing technique so that entities can be completely grounded. Additionally, minor misclassifications observed during evaluation, such as this or mosquito, suggest that annotation patterns may influence tagging accuracy in particular contexts.
Future work will focus on developing training datasets for predictive tasks and expanding Survice-BERT with additional NER tags. We also plan to build multilingual versions fine-tuned on datasets in multiple languages or via translation APIs. Furthermore, we aim to develop improved pre- and post-processing techniques for normalization and performance enhancement. Moreover, we can provide a web-based or standalone application of the Survice-BERT to apportion the model outputs to end users, including public health officials, epidemiologists, and other domain researchers. The Survice-BERT model will continue to be freely available on GitHub (71).
Looking ahead, the inevitability of future pandemics, including the unknown “Disease X,” underscores the urgency of strengthening public health surveillance systems. This study contributes to continuous monitoring, timely detection, and predictive modeling for epidemic prevention. In conclusion, Survice-BERT has the potential to enhance public health preparedness and resilience in the face of future pandemics.
